Abstract:
Running emotional voice conversion (EVC) in real-time using live input from a microphone, while maintaining the quality of the converted voice and achieving low latency, remains an underexplored area. Some deep learning speaker voice conversion (SVC) methods attempt to read speech frames in a streaming fashion to accelerate the real-time conversion. However, these methods only deal with short-term speech features, ignoring the long-term prosody features that are crucial in EVC. To address this issue, we propose a hybrid EVC framework in this study. The framework consists of short- and long-term filters to separately convert the prosody (F0) features of different temporal levels, ranging from micro-prosody to sentences, which are captured using the continuous wavelet transform. Our experiments show that the proposed framework achieves competitive results for both similarity and naturalness in real-time conversion. We also provide the demo voices and videos to show the performance.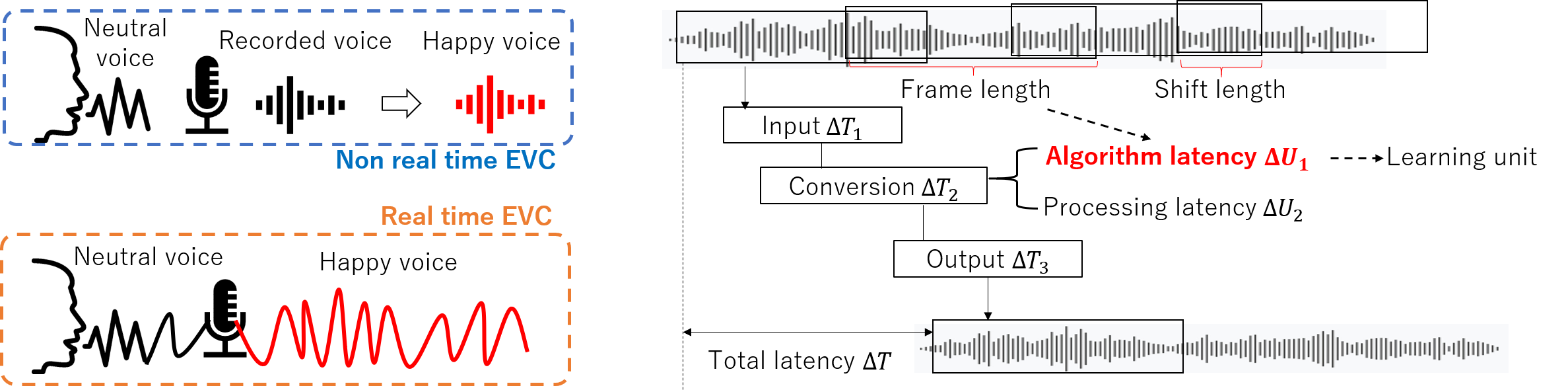
Fig. 1: Framework of proposed real-time emotional voice conversion.
Speech Samples:
Experimental Setup:
(1) Baseline : As there are no comparable deep learning-based real-time EVC methods in the literature, we reimplemented the earliest DNN-based EVC model [1], with the streaming conversion method used real-time speaker VC tasks [2].
(2) SFEVC: This is the newest non-real-time EVC method, adopting the Source-Filter Networks to decouple Speaker-independent Emotions for Voice Conversion. [3].
(3) Proposed : This is the proposed real-time EVC using hybrid filtering for short-term and long-term features conversion, separately. For ablation study, S-o represents using the short-term filter only, S+L represents using both the short-term and long-term filters.
Speech Naturalness Evaluation |
||||
|---|---|---|---|---|
| Source | Baseline | SFEVC | Proposed (S+L) | Target |
Emotion similarity evaluation (Ablation Study) |
|||
|---|---|---|---|
| Source | S-o | S+L | Target |
Video Samples:
Samples in the real-world Tele-operated Robot uisng the High tension emotion voice data. Left: Operator speak in a neutral voice; Right: Real time converted high-tension voice output by the tele-robot
References
[1] Zhaojie Luo, Tetsuya Takiguchi, and Yasuo Ariki, “Emotional voice conversion using deep neural networks with mcc and f0 features,” in 2016 IEEE/ACIS 15th International Conference on Computer and Information Science (ICIS). IEEE, 2016, pp. 1–5.[2] Tomoki Toda, Takashi Muramatsu, and Hideki Banno, “Implementation of computationally efficient real-time voice conversion,” in INTERSPEECH 2012, Portland, Oregon, USA, September 9-13, 2012. 2012, pp. 94–97, ISCA.
[3] Zhaojie Luo, Shoufeng Lin, Rui Liu, Jun Baba, Yuichiro Yoshikawa, Hiroshi Ishiguro, “Decoupling speaker-independent emotions for voice conversion via source-filter networks,” IEEE/ACM Transactions on Audio, Speech, and Language Processing (2022).